HDFS/HBase技术报告·分布式数据库设计架构的全面解析
Hadoop生态的分布式数据库
1、什么是分布式数据库?
从狭义的理解就是分布式关系型数据库,主要特指目前热门的NewSQL。
从广义的理解,分库分表的传统关系型数据库,传统关系型数据库集群,关系型数据库的主从架构,分布式KV数据库(例如:HBase),分布式文档数据库(例如:MongoDB),分布式关系数据库(例如:TiDB)等,统称为分布式数据库。
本文主要讲Google一脉相承的Hadoop生态下的分布式数据库架构设计,以及传统RDBMS与NoSQL的分布式环境下的一致性对比。
2、Hadoop HDFS的数据存储模型
最早Google发明了GFS分布式文件系统,之后对应的开源项目就是鼎鼎大名的Hadoop HDFS。
GFS/HDFS的特点表现在顺序的、成块的、无索引的向文件块中写入数据,并在集群环境中按块(block)均匀分布存储,使用时再根据MapReduce、Spark的并行任务,按块批次的读取分析。这样就把写入和并行读取的性能发挥到了极致,具备了任何建立索引的数据库都无法比拟的读写速度。
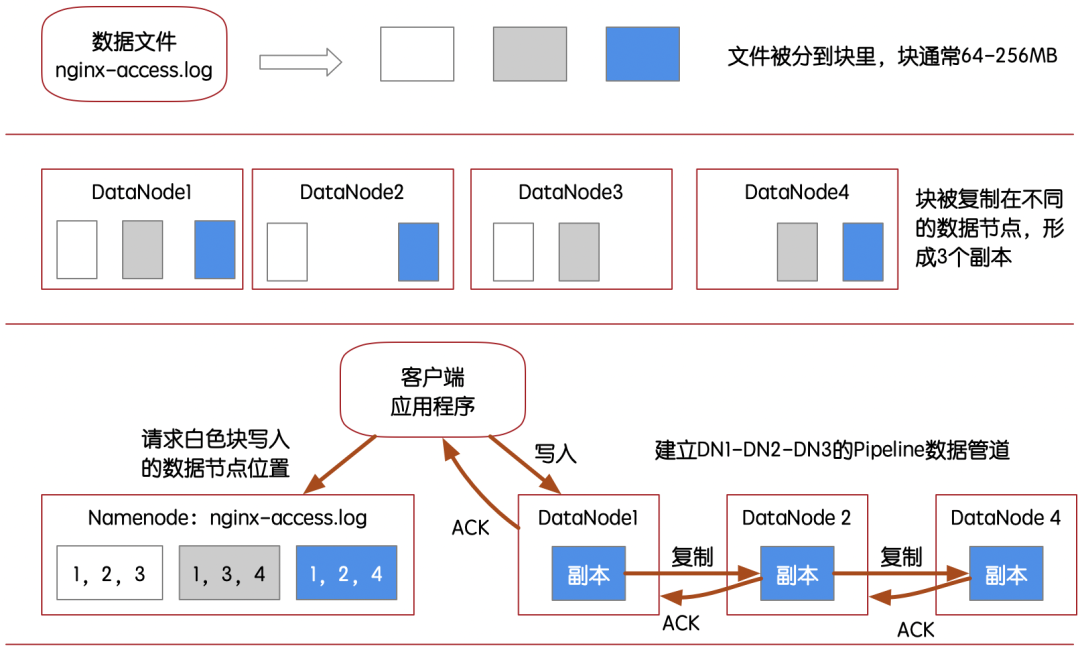
HDFS的数据写入结构示意图
上图是一个写入HDFS数据的例子,我们需要知道HDFS这些事情:
需要写入HDFS的文件会被分成数据块,一个数据块通常是64M或者128M。
数据块在HDFS集群中默认有三个副本,平均分配在不同的DataNode数据节点上。
由于HDFS的分布式架构是中心化管理,因此并没有数据节点主副的概念,只有顺序的概念,所有数据节点都是存储数据块副本的,全部通过namenode节点安排数据节点的写入顺序。
数据节点的写入过程就像一个数据管道,根据客户端就近原则,形成数据节点的排队,当第一个节点写入数据包后,然后再向数据管道的下一个数据节点复制,以此类推,并得到完成确认。
3、HBase的架构设计
为了更好的理解HBase/Bigtable,一定需要先铺陈一下它们所依赖的分布式文件系统基础环境,然后再看看这些巧夺天工的分布式数据库设计如何形成的。
由于GFS/HDFS集群的高性能设计是建立在放弃随机查找的基础之上。那么如何既能拥有随机查找的特性,又能充分利用好HDFS/GFS的集群优势,而且还能在分布式环境下,具备数据写入的强一致性呢?这才涌现出了HBase/Bigtable这类基于分布式文件系统的分布式数据库。
但大家要注意了,实际上HBase/Bigtable的随机查找设计目标并不是解决复杂的join关联查找或二次索引范围查找,而是实现简单的一个K-V查询模型,满足海量数据的存放条件下,通过主键查找结果,能达到毫秒级响应的数据库。
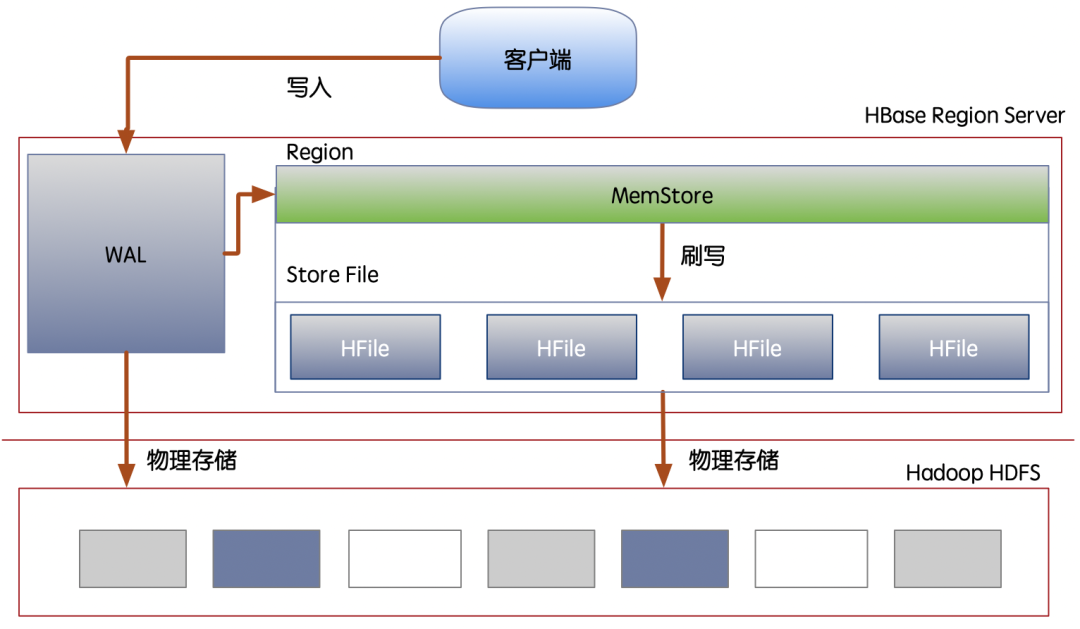
HBase的数据写入结构示意图
上图就是HBase的写入过程以及HDFS作为物理层支撑的架构示意图。
HBase按照LSM-Tree索引加上SSTable数据结构建立了NoSQL常用的数据存储模型。写入过程分成了下面几个部分:
客户端向HBase的Region Server写入数据,会首先进入到WAL(Write-Ahead-Log)预写日志中,然后再进入到选择的Region的MemStore中,那这个WAL的目的是什么呢?保命用的!因为一旦Region Server断电或异常崩溃,MemStore的数据是在内存里,肯定就丢了,MemStore恢复的时候就靠WAL存的日志数据了。MemStore真正同步数据后,WAL才会从本地写入HDFS,否则回滚。
Region的MemStore是一个放在内存里的高速操作区,MVCC事务操作,最近写入记录读取都可以在此处快速完成,当数据在MemStore写满后,就会刷入到Store File磁盘存储区。
Store File存储区就是不断通过memstore刷盘而形成的HFile,每个HFile默认分配128M,大小正好与HDFS的一个数据块(block)一致,HFile的物理位置就是存储在HDFS的每个数据块中,HFile就是不可更改的了,并通过HDFS的副本机制,形成三副本保证数据的可靠性。
3、HDFS与HBase的协作配合
从上述的HDFS和HBase系统的配合中(GFS与BigTable同理)我们可以看到Hadoop生态体系设计的巧妙结构:
HDFS对于大文件块的顺序写入,批量分析,HDFS的无索引、顺序写入、管道复制机制充分体现了Google的暴力美学~解决问题的方式务实、简单、直接、高效。
HBase作为列簇设计的K-V数据库,又实现了细腻入微的设计思想,通过LSM-Tree索引和SSTable数据结构建立起原生数据库存储层。
HBase机制上WAL、MemStore、StoreFile形成数据操作的多元素协作。
HBase架构上HRegion Server、HRegion、HLog、HStore层层嵌套,形成分布式数据库的集群化能力。
最关键的就是HBase与HDFS的分工思想,HBase解决业务数据记录写入,K-V随机查找(毫秒级),由Region Server控制的行级事务等一些列分布式数据库特征;而HDFS解决小文件汇聚成大文件的高性能处理,分布式文件系统的海量存储,数据多副本的可靠性,以及成为Mapreduce、Spark、Hive等其他框架与HBase之间协作的基础平台。

分布式环境下数据库的一致性
首先数据库的一致性,从传统的关系型数据库讲,就是指在一个库中一次业务操作,无论涉及多少张表,多少行集,要么都失败,要么都成功,不能出现结果和预想的不一致,就是所谓的事务ACID特性中最重要的强一致性。
事务具有4个特征,分别是原子性、一致性、隔离性和持久性,简称事务的ACID特性;
(一)、原子性(atomicity)
一个事务要么全部提交成功,要么全部失败回滚,不能只执行其中的一部分操作,这就是事务的原子性
(二)、一致性(consistency)
事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。
(三)、隔离性(isolation)
事务的隔离性是指在并发环境中,并发的事务相互隔离的,一个事务的执行不能不被其他事务干扰。
(四)、持久性(Durability)
一个事务一旦成功提交,它对数据库的改变必须是永久的,即便是数据库发生故障也应该不回对其产生任何影响。
我们重点说说分布式环境下数据库的一致性(consistency)特点:
1、MySQL的分布式一致性
一个特别典型的例子就是MySQL的主从复制架构:异步,半同步,全同步。
异步:尽管主库保证了数据的强一致性,但是数据一旦写给binlog,主库就无视了从库的一致性,继续忙自己的事情,那么这个过程就是异步的,从库从binlog中拿到结果再重放保证与主库的一致性,我们把这个过程叫做最终一致性。
半同步:MySQL 主库写入binlog后,至少集群中任意一个MySQL从库反馈主库,它同步成功了,那么主库就继续忙自己的事了,我们可以把这个过程称为弱一致性。
全同步:自然不用想了,MySQL主库写入binlog,集群其他节点都要重放后,报告同步成功了,主库才会忙其他事情,这就是分布式环境的强一致性了!
弱一致性是在强一致性和最终一致性中寻找一个平衡,至少有一个备份点是必须与主保持一致的,那么数据的可靠性是不是就提升了,同时性能上也不至于太差了。
2、NoSQL的分布式一致性
其次纠正一个错误的观点,NoSQL不能都视之为弱一致性。得具体看是哪个NoSQL框架,例如:MongoDB我们认为是NoSQL,它在副本集模式下,可以灵活地设置一致性规则,其中majority选项的意思是主库写入oplog后,大多数成员需要确认才行。
这个够挠头吧,怎么又来了个大多数,这岂不是在弱一致性和强一致性之间又出现了一种一致性模式,可实际就是这样。
我们再回来谈本文重点提到的一个NoSQL:HBase,它可的确是分布式环境下的强一致性啦,是不是颠覆了你对NoSQL的认知了!
因为HBase的是基于行级的事务,也就是说当一次写入记录的过程,一定是一个Region只分配一个Region Server写入,而且对于行级数据的操作要不写入成功,要不失败。如果一个节点挂了,恢复节点在没有恢复完数据之前就是不可用了。
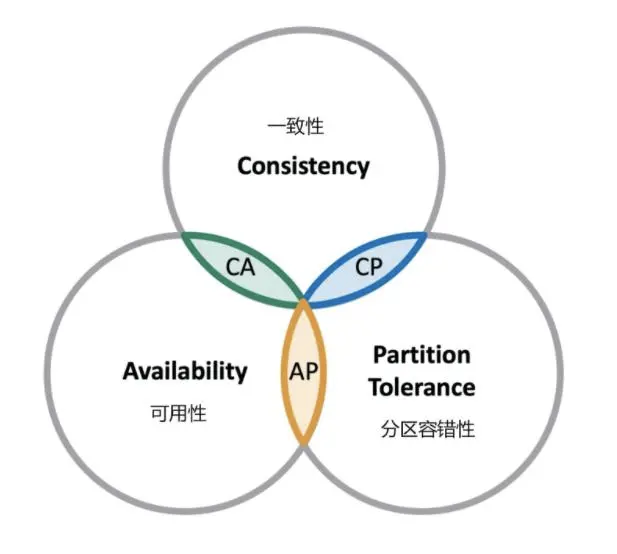
HBase在CAP定理中保证了CP,舍弃了A:一致性C(HBase同一时间写入不同节点的数据必须一致),容错性P(即便有节点出错,系统还能正常运行),但是这个可靠性A就有问题(必须等待节点恢复完成,对请求就不能立刻有响应了)
最后再说说有些NoSQL的弱一致性为什么就可以被接受?
回顾一下最开始的MySQL的异步模式复制,它为什么是MySQL的默认复制模式?
若满足最终一致性,那么这类分布式系统选择了CAP定理中的AP,就是说为了保证系统内部无论是否出错,都会给客户响应。代价就是分布式各节点的数据副本有可能不一致,但这个问题不是此类系统业务最在乎的事情,往往系统的高性能,并能为客户端提供快速响应力才是关键目标,MySQL的默认主从复制如此,有些NoSQL亦如此。
传世的关系模型
首先从数据库的表达力来讲,并不是NoSQL要强于关系模型,事实上SQL的表达力是无出其右的,否则就不会兴盛四十年而不衰,就不会有Hive SQL、Spark SQL、Presto、Impala这些以支持SQL交互为起点的NoSQL上层框架存在的必须性。
看吧,还没到NewSQL这一代的时候,返祖的现象就已经出现了!
1、我们再温故知新一下什么是关系模型
关系型模型之父Edgar F. Codd,在1970年Communications of ACM 上发表了《大型共享数据库数据的关系模型》这就是永恒的经典,关系模型的语义设计达到了40年来普世的易于理解,语法的嵌套,闭环,完整。

关系型模型之父Edgar F. Codd
原始的关系模型:
结构(structure)结构的主要特征就是关系(relation),表格就是实现形式关系定义在类型(type or domain)的基础上,属性(attribute)就是类型的实际值,N个属性就是描述了N元关系每个关系都至少有一个候选键(唯一标识符),它是属性的组合,通常只有一个属性。元组(tuple)就是属性的集合
完整性(integrity)实体完整性规则:主键属性不允许null,不能存在任何不匹配的外键取值。
操作(manipulation)关系的运算符集合(限制、投影、积、交、并、差、连接),关系表达式赋值关系(例如:关系1 并 关系2赋值给关系3),操作的输入关系和输出关系,形成了闭包(closure)性质,就可以写出嵌套表达式
原始理论具体到实现再翻译成我们好理解的描述:结构、完整性、操作就构成了现在传统数据库的关系模型。
结构:就是我们经常要先对数据库预先定义的表名和字段(名称、类型)
完整性:就是表的主键不能为空,表与表之间的主外键关联必须保证是完整的,外键一定是能找到主键的。
操作:那就是SQL表达式啦,SQL的子查询就是典型的闭包(Closure),可以形成嵌套表达式。
2、虽然NoSQL很火,但我们这个世界没法 NO SQL
HBase/Bigtable可以认为是NoSQL的典型代表
恰恰NoSQL发展至今,出现了Hive SQL,Spark SQL,Presto,Impala,直到基于Google Spanner论文的TIDB,CockroachDB等NewSQL的不断涌现,才让我们用实践证明,无论是NoSQL也好,NewSQL也罢,它们的查询语言客户端又回到了SQL。
我们只是在大数据领域需要替换关系型数据库的存储逻辑,使得数据库更分布式化,更容易实现扩展。这是符合单机性能到了天花板后,必须横向扩展的硬需求,但这也并不是说关系模型就过时了!
像HBase/Bigtable这样的NoSQL,大多数采用了LSM-Tree的索引机制,来替换RDBMS的B-Tree机制,这么做都是为了能实现内存与磁盘,写入与查找的更平衡利用。
它们又用数据分片的水平切分替换RDBMS的分库分表的垂直切分,让节点与集群的水平伸缩性更为自动化,而不是像分库分表那样进行人工复杂的介入。
TiDB这些NewSQL的出现恰恰是在缝合关系模型和分布式存储之间的裂缝,面向客户端依然是关系模型,强化分布式业务更新的强一致性(分布式事务,这是最难的最复杂的地方),面向存储则坚定的选择K-V模型。
例如TIDB的TIKV集群采用的就是rocksdb,rocksdb的底层索引机制又和HBase/Bigtable采用相同设计机制的又一个nosql成员。
因此并不是Google的Spanner论文以及F1,TiDB这些实现技术开了历史的倒车,恰恰是对狂热的nosql运动的一种反思,对成为经典的SQL关系模型理论的一种认真思考和融合。
任何新技术都是站在前辈的基础上开启的,我们总要回头望望,反思新技术的运用到底我们得到了什么,又失去了什么!
文章来自公众号读字节(专注分布式架构和大数据技术)原创。若转载本文,请务必注明公众号来源,感谢阅读和转发。
原文地址链接:传世的关系模型,巧夺天工的分布式数据库设计
原文转载:http://www.shaoqun.com/a/695756.html
heap:https://www.ikjzd.com/w/2012
亚马逊t恤:https://www.ikjzd.com/w/1932
Hadoop生态的分布式数据库1、什么是分布式数据库?从狭义的理解就是分布式关系型数据库,主要特指目前热门的NewSQL。从广义的理解,分库分表的传统关系型数据库,传统关系型数据库集群,关系型数据库的主从架构,分布式KV数据库(例如:HBase),分布式文档数据库(例如:MongoDB),分布式关系数据库(例如:TiDB)等,统称为分布式数据库。本文主要讲Google一脉相承的Hadoop生态下的
sonar:https://www.ikjzd.com/w/215
zappos:https://www.ikjzd.com/w/330
moss:https://www.ikjzd.com/w/1653
备战Q4,布局选品、打好关键词广告这些准备再不做就晚了:https://www.ikjzd.com/home/3993
老公说怀不上孩子 就别爱爱了:http://lady.shaoqun.com/m/a/271532.html
装睡屁股转过去让滑进去 挺进白嫩老师下面:http://lady.shaoqun.com/m/a/247311.html

Comments
Post a Comment