SGA: allocation forcing component growth分析
1.问题现象
20年12月31日,数据库应用人员反映2020-12-31 12:40:10存在告警,过了几分钟之后业务恢复正常。
表现的状态:Connect to database time out, please check db status!
因为业务反馈的内容很有限,所以我们取了12月31日12:00-13:00的AWR进行分析。

可以看到AAS并不是很高,AAS=755.39/32.05=23.57
(备注:AAS是衡量快照时间内数据库负载的重要指标)
通过AWR观察
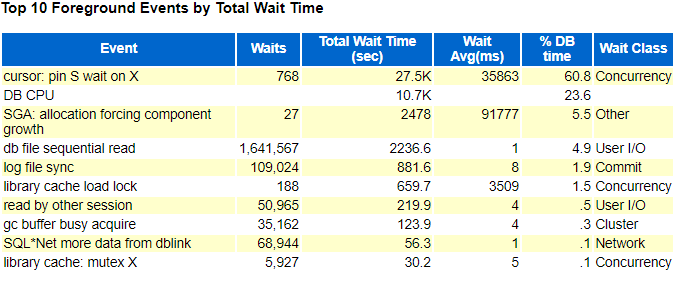
可以看到有大量的cursor:pin s wait on X和SGA:allocation forceing comonent growth等待事件。
2.问题分析
通过MOS因为ASMM和AMM使用自动调整内存管理方案。 启用这些架构中的任何一种,都可以在SGA中的各个组件(例如缓冲区高速缓存和共享池)之间自动移动内存,以便在其中一个组件中填充内存请求导致的。
SQL> show parameter sgaNAME TYPE VALUE------------------------------------ ----------- ------------------------------lock_sga boolean FALSEpre_page_sga boolean FALSEsga_max_size big integer 206336Msga_target big integer 0SQL> show parameter targetNAME TYPE VALUE------------------------------------ ----------- ------------------------------archive_lag_target integer 0db_flashback_retention_target integer 1440fast_start_io_target integer 0fast_start_mttr_target integer 0memory_max_target big integer 206336Mmemory_target big integer 206336Mparallel_servers_target integer 32pga_aggregate_target big integer 0sga_target big integer 0SQL> show parameter pgaNAME TYPE VALUE------------------------------------ ----------- ------------------------------pga_aggregate_target big integer 0SQL>
通过检查发现数据库使用的AMM的内存管理方式,自动内存管理automatic memory management(以下均称AMM)是oracle 11g新推出的新特性,意在对实例中的PGA和SGA进行自动管理。AMM是自动共享内存管理automatic shared memory management(ASMM)的拓展
ORACLE 11g AMM 的引入, 组合出来有 5 种内存管理形式.
自动内存管理(AMM) : memory_target=非0,是自动内存管理,如果初始化参数 LOCK_SGA=TRUE,则 AMM 是不可用的。
自动共享内存管理(ASMM): 在memory_target=0 and sga_target为非0的情形下是自动内存管理
手工共享内存管理 : memory_target=0 and sga_target=0 指定 share_pool_size 、db_cache_size 等 sga 参数
自动 PGA 管理 : memory_target=0 and workarea_size_policy=auto and PGA_AGGREGATE_TARGET=值
手动 PGA 管理 : memory_target=0 and workarea_size_policy=manal 然后指定 SORT_AREA_SIZE 等 PGA 参数,一般不使用手动管理PGA。
但是11g推出了自动内存管理(AMM)新特性,该特性引入后,虽然减轻了DBA手动设置共享内存的负担,shared pool和buffer cache及其它几个component可以根据需要自动调整大小,避免ora-4031的错误,但经常出现在shared pool和buffer cache之间发生频繁shrink/grow操作的现象,在一些高并发环境下,会刷出一批共享池对象,并间歇性持有shared pool latch,library cache lock等共享池latch,从而引发数据库性能问题的风险,极端情况下,会导致数据库性能短时间内极速下降。而且如果一旦刷出共享池对象,就会引起数据库大量游标失效,随后的解析会导致大量library cache及cursor等待事件。这也是为什么在AWR的前台等待事件中伴随着大量的cursor:pin s wait on X等待事件的原因。
SQL> set linesize 600SQL> col component for a25SQL> col oper_type for a15SQL> col oper_mode for a10SQL> col parameter for a25SQL> col initial_size for 999999999999SQL> col final_size for 99999999999SQL> select component, 2 oper_type, 3 oper_mode, 4 parameter, 5 initial_size, 6 target_size, 7 final_size, 8 status, 9 start_time, 10 end_time as changed_time 11 from V$SGA_RESIZE_OPS 12 where to_char(end_time,'yyyy-mm-dd hh')='2020-12-31 12' 13 order by end_time;COMPONENT OPER_TYPE OPER_MODE PARAMETER INITIAL_SIZE TARGET_SIZE FINAL_SIZE STATUS START_TIME CHANGED_TIME------------------------- --------------- ---------- ------------------------- ------------- ----------- ------------ --------- ------------------- -------------------shared pool SHRINK DEFERRED shared_pool_size 19327352832 1.8790E+10 18790481920 COMPLETE 2020-12-31 12:38:59 2020-12-31 12:40:42DEFAULT buffer cache GROW DEFERRED db_cache_size 51002736640 5.1540E+10 51539607552 COMPLETE 2020-12-31 12:38:59 2020-12-31 12:40:42DEFAULT buffer cache SHRINK IMMEDIATE db_cache_size 51539607552 5.1003E+10 51002736640 COMPLETE 2020-12-31 12:40:42 2020-12-31 12:40:44shared pool GROW IMMEDIATE shared_pool_size 18790481920 1.9327E+10 19327352832 COMPLETE 2020-12-31 12:40:42 2020-12-31 12:40:44DEFAULT buffer cache SHRINK IMMEDIATE db_cache_size 51002736640 5.0466E+10 50465865728 COMPLETE 2020-12-31 12:40:44 2020-12-31 12:40:47shared pool GROW IMMEDIATE shared_pool_size 19327352832 1.9864E+10 19864223744 COMPLETE 2020-12-31 12:40:44 2020-12-31 12:40:47
可以看到在12:38-12:40出现了sharepool增长和buffer cache的shrink,buffer cache会刷出部分对象,会导致一些SQL语句被重新硬解析。
备注:buffercache的大小可以从v$sga_dynamic_components进行查询
然后我们再观察AWR的SGA组件明细

从AWR报告看到,KGH: NO ACCESS 类型内存占用已经接近600M左右。内存参数仅仅配置了memory_target,没有配置SHARED_POOL_SIZE, DB_CACHE_SIZE等。KGH: NO ACCESS 是内存在shared pool和db cache之间调节的一个中间状态,正常情况不超过100-200M,而且很快消失,内存调节过于频繁导致卡死在KGH: NO ACCESS,进而可能导致可用shared pool不足,导致数据库出现性能问题。
3.问题处理
通过以往的经验看,SGA_TARGET的稳定性高于memory_target,可以考虑不使用memory_target,而是用SGA_TARGET和pga_aggregate_target的组合。
所以建议如下:
1.关闭自动内存扩展,采用 手工共享内存管理或者自动共享内存的方式,但是需要注意的是Disable AMM/ASMM也可以作为一个方法,但是缺点是: 碰到ora-4031的几率会比自动内存管理大.
2.设置SHARED_POOL_SIZE, DB_CACHE_SIZE,确保这些池有一个最小值,从而减少过度调节。
3.设置alter system set "_memory_broker_stat_interval"=999; 降低调节频率,设置resize的频率不能少于16分钟
4.重启实例,清空当前异常内存分配。
最后,我们采用的方式是,使用ASMM方式,将大页启用
SQL> show parameter target NAME TYPE VALUE------------------------------------ ----------- ------------------------------archive_lag_target integer 0db_flashback_retention_target integer 1440fast_start_io_target integer 0fast_start_mttr_target integer 0memory_max_target big integer 0memory_target big integer 0parallel_servers_target integer 32pga_aggregate_target big integer 50Gsga_target big integer 280GSQL> show parameter db_cache_sizeNAME TYPE VALUE------------------------------------ ----------- ------------------------------db_cache_size big integer 100GSQL> show parameter shared_pool_sizeNAME TYPE VALUE------------------------------------ ----------- ------------------------------shared_pool_size big integer 60G
大页使用情况
[oracle@xsdbd31 ~]$ grep -i huge /proc/meminfoAnonHugePages: 1587200 kBHugePages_Total: 143380HugePages_Free: 13567HugePages_Rsvd: 13548HugePages_Surp: 0Hugepagesize: 2048 kB
参考链接:
https://blogs.oracle.com/database4cn/3-v3
https://cloud.tencent.com/developer/article/1424411
MOS:ORA-04031 in 11g & 11gR2, Excess "KGH: NO ACCESS" Memory Allocation ( Doc ID 1127833.1 )
太久没有写博客了,前一阵子被催着来写,接下来的时光,希望和博客园的大佬的共享数据库知识。
原文转载:http://www.shaoqun.com/a/512448.html
铭宣海淘:https://www.ikjzd.com/w/1551
landing:https://www.ikjzd.com/w/2368
1.问题现象20年12月31日,数据库应用人员反映2020-12-3112:40:10存在告警,过了几分钟之后业务恢复正常。表现的状态:Connecttodatabasetimeout,pleasecheckdbstatus!因为业务反馈的内容很有限,所以我们取了12月31日12:00-13:00的AWR进行分析。可以看到AAS并不是很高,AAS=755.39/32.05=23.57(备注:AAS
易佰:易佰
打折网:打折网
一碗面条名四海:刀削面 - :一碗面条名四海:刀削面 -
2020国际旅游财富峰会迎来倒计时:2020国际旅游财富峰会迎来倒计时
肇庆西江三峡自驾游该怎么走呢?:肇庆西江三峡自驾游该怎么走呢?